
World Wide Web
Allgemein
Das World Wide Web (kurz WWW) ist ein System von weltweit über das Internet verknüpften Webseiten. Webseiten sind Hypertext-Dokumente, die über sog. Hyperlinks miteinander verbunden sind. Ein Hyperlink (kurz Link) ist ein Verweis auf eine andere Webseite oder auf eine andere Stelle auf der gleichen Webseite, über den automatisch die neue Quelle aufgerufen wird. Was heute ganz selbstverständlich klingt, war vor der Erfindung des WWW so nicht möglich. Das Arbeiten mit verschiedenen Quellen glich eher der Suche in verschiedenen Büchern einer Bücherei, bei der man sich immer nur ein Buch gleichzeitig ausleihen darf. Ein Quellenverweis war hier lediglich ein Hinweis auf eine andere Quelle. Sollte zur neuen Quelle gewechselt werden, musste das Buch zurück in das Bücherregal gestellt werden, das neue Buch gesucht, herausgenommen und die entsprechende Seite aufgeschlagen werden. Dies Alles erledigen Hyperlinks (Links) in Hypertext-Dokumenten (Webseiten) seit dem WWW automatisch, durch einen einfachen Mausklick auf einen Link.
Entstehung
Die technischen Voraussetzungen für das WWW wurden 1989 von Tim Berners-Lee in Zusammenarbeit mit Robert Cailiau im Rahmen eines Forschungsprojekts an der Forschungseinrichtung CERN entwickelt. Ziel des Systems war es, Forschungsergebnisse flexibel unter den Wissenschaftlern austauschen zu können. Dies sollte dadurch erreicht werden, indem die Forschungsergebnisse untereinander verbunden (verlinkt) werden, damit ein Geflecht (Web) aus wissenschaftlichen Artikeln entsteht. Ähnliche Ansätze gab es schon vorher. Das WWW war aber dahingehend neu und einzigartig, dass es zum einen nur unidirektionale Links verwendet, d. h. die Quelle auf die verlinkt wird muss nicht angepasst werden und zum anderen Tim Berners-Lee auf eine Patentierung und daraus resultierende Einnahmen verzichtete. Somit war das WWW von Anfang an ohne Lizenzkosten und Lizenzstreitereien, einfach und flexibel erweiterbar, was zu seiner immensen Verbreitung führte.
Tim Berners-Lee erstellte 1990 die erste Webseite des WWW und ein Anzeigeprogramm zum Darstellen der Seite, aus dem sich später der erste Browser entwickelte. 1991 veröffentlichte er das WWW-Projekt schließlich in einem Newsgroup-Beitrag und machte es damit weltweit verfügbar. 1993 folgte dann der erste voll funktionsfähige Webbrowser namens Mosaic der dem WWW endgültig zum Durchbruch verhalf. Waren es 1993 noch erst ca. 130 Webseiten, umfasste das Web bereits vier Jahre später schon über eine Million Webseiten.

Funktionsweise
Technisch betrachtete ist das WWW ein System von tausenden weltweit verteilten Webservern, auf denen Webseiten gespeichert und abrufbar sind und mit Hilfe von Webbrowsern aufgerufen werden können. Webseiten können dabei Informationen in Form von Text, Bildern sowie abspielbaren Audio- und Video-Dateien enthalten. Damit das WWW funktioniert, sind drei elementare Technologien entscheidend. Zum Abrufen von Webseiten wird das Protokoll HTTP verwendet, der Aufbau einer Webseite wird mit Hilfe von HTML definiert und über URL‘s werden Webseiten als Web-Ressourcen ansprechbar. Darüber hinaus gibt es noch viele andere Technologien, wie z. B. HTTPS, CSS oder JavaScript, die heutzutage beim Webdesign verwendet werden.

Grafische Darstellung einiger weniger Sites im World Wide Web um en.wikipedia.org am 18. Juli 2004; Urheber: Chris 73
HTTP
HTTP steht für Hypertext Transfer Protocol und ist ein zustandsloses Protokoll mit dem Webseiten mit einem Webbrowser geladen werden können. HTTP ist dabei ein Protokoll der Anwendungsschicht, das auf die darunterliegenden Protokolle TCP und IP aufbaut. Ein Browser fordert dabei eine Webseite von einem Webserver mit Hilfe eines sog. HTTP-Requests an, der u. a. eine URL enthält, die genauer spezifiziert wie und von wo eine Webseite geladen werden soll. Der Server antwortet dann mit einem sog. HTTP-Response, der den Inhalt der Webseite enthält.

HTML
HTML steht für Hypertext Markup Language und ist eine sog. Auszeichnungssprache zur Definition von Webseitenelementen, die dann von Webbrowsern richtig erkannt und dargestellt werden können. HTML definiert dabei aber nur um was für Elemente es sich handelt, z. B. eine Überschrift oder ein Textelement. Die eigentliche Formatierung, d. h. wie ein Element dargestellt wird (Farbe, Größe, etc.), wird mit Hilfe der Stylesheet-Sprache CSS (Cascading Style Sheets) definiert. HTML wird vom „World Wide Web Consortium“ (kurz W3C) und der „Web Hypertext Application Technology Working Group“ (kurz WHATWG) spezifiziert und weiterentwickelt. Die derzeit aktuellste Version ist HTML5.

URL
URL steht für Uniform Resource Locator und dient dazu Webressourcen, wie z. B. Webseiten, eindeutig zu identifizieren und ansprechbar zu machen. Um eine Webseite oder eine Unterseite einer Webseite im Browser aufzurufen, reicht nicht einfach die IP-Adresse des entsprechenden Webservers, da dieser viele Webseiten und Unterseiten bereitstellen kann. Außerdem wird mit einer URL auch die Zugriffsmethode, das sog. Schema, definiert. Ein Schema ist dabei in vielen Fällen gleichzusetzen mit dem zu verwendenden Netzwerkprotokoll. Eine URL besteht damit aus einem Schema (Zugriffsmethode) und einem sog. Schema-spezifischen Teil, der die Webressource adressiert. Die beiden Teile werden durch Doppelpunkt getrennt. Der Schema-spezifische Teil besteht wiederum aus der Domäne des Webservers und dem Pfad in dem die eigentliche Webseite als Datei liegt. Außerdem können im Schema-spezifischen Teil auch noch sog. Query-Strings und Fragmente spezifiziert werden. Query-Strings beginnen mit einem Fragezeichen und enthalten meistens Parameter, die bei der Webseiten-Anfrage an den Server übergeben werden sollen. Fragmente beginnen mit einem Doppelkreuz und dienen i. d. R. dazu, an eine spezielle Stelle auf einer Seite zu springen.

Webbrowser
Ein Webbrowser (kurz Browser) ist eine Applikation zum Darstellen von Webseiten. Browser können zum Einen HTML und CSS interpretieren, um eine Webseite richtig darzustellen und die Elemente der Webseite richtig zu formatieren. Weiter können Browser den Links von Webseiten folgen, um andere Webseiten auf anderen Webservern aufzurufen und zwischen den verschiedenen Seiten flexibel zu navigieren. Außerdem können Browser JavaScript-Code ausführen, wodurch Webseiten interaktiv werden und so im Browser ganze Webapplikationen ausgeführt und bedient werden können.
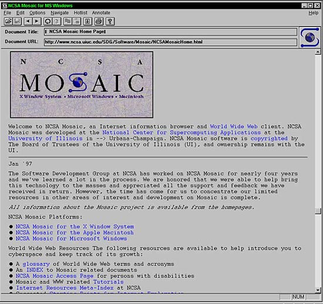
Der erste voll funktionsfähige Webbrowser war der „NCSA Mosaic“ der 1993 am „National Center for Supercomputing Applications“ (kurz NCSA) von Eric Bina und Marc Andreesen entwickelt wurde und dem WWW zum Durchbruch verhalf. Marc Andreesen gründete danach das Unternehmen „Netscape Communications“ und brachte 1994 den Browser „Netscape Navigator“ erfolgreich auf den Markt. Danach folgte 1995 der Internet Explorer von Microsoft der zusammen mit Windows 95 ausgeliefert wurde und von da an bis heute fester Bestandteil von Windows ist. Bereits 1996 wurde der weniger bekannte Browser Opera von der Firma „Opera Software“ veröffentlicht. Opera war jedoch in den ersten Jahren kostenpflichtig und wurde erst 2005 kostenlos und werbefrei. Ab 2003 integrierte Apple den Browser Safari als Standardbrowser in sein Betriebssystem OS X. 2004 folgte dann der unabhängige Browser Firefox der Firma Mozilla Corporation. Als Letzter, der heute weit verbreiteten Browser, kam Chrome von Google 2008 auf den Markt. Ab Windows 10 liefert Microsoft den Browser „Microsoft Edge“ als Standardbrowser aus, während der Internet Explorer aber immer noch in Windows integriert bleibt.

Internet Explorer

Opera

Mozilla Firefox

Google Chrome
Webserver
Webserver sind Server, die Webseiten als WWW-Dienst zum Abrufen durch Webbrowser zur Verfügung stellen. Ein Webserver ist dabei aber lediglich eine Software, die über definierte Protokolle (meist HTTP) auf Anfragen von Webbrowsern reagiert und Dokumente (Webseiten) an diese als Antwort übermittelt. Somit können Webserver auf fast jedem Computer betrieben werden. In der Praxis werden dafür meist speziell dafür ausgelegte Server bei Providern angemietet, welche die Webseiten dann zur Verfügung stellen.
Die bekanntesten frei verfügbaren Webserver-Programme sind „Apache Tomcat“ und „nginx“. Der „Apache Tomcat“ ist derzeit der am meisten verbreitetste Webserver und kann kostenlos auf den meisten gängigen Betriebssystemen betrieben werden. Der Webserver „nginx“ kann hingegen nur auf Linux-Systemen eingesetzt werden.


Microsoft stellt ebenfalls einen Webserver zur Verfügung, der kostenlos auf Windows-Systemen verwendet werden kann. Dazu müssen lediglich in den Windows-Funktionen die „Internetinformationsdienste“ aktiviert werden. Der Microsoft-Webserver steht an zweiter Stelle bei der Verbreitung, ist aber an den Kauf eines Windows-Betriebssystems gebunden und steht auch nur auf Windows-Betriebssystemen zur Verfügung.

Suchmaschinen
Eine Suchmaschine ist ganz allgemein ein Programm zum Suchen von Informationen in Rechnernetzwerken. Internetsuchmaschinen sind aber keine lokal gespeicherten Programme sondern Webdienste die mit dem Browser genutzt werden können. Eine Suchmaschine fängt aber nicht dann an zu Suchen, wenn die Suchanfrage kommt, da das viel zu lange dauern würde, sondern baut im Vorfeld einen sog. Suchindex auf. Ein Suchindex enthält dazu im Wesentlichen die Webadresse einer Webseite und deren wichtigsten Stichworte. Wird nun eine Suchanfrage an die Suchmaschine gestellt sucht sie in ihrem Index nach diesen Stichworten und gibt dann die Webseiten mit den passenden Stichworten, sortiert nach ihrer Relevanz, zurück. Die Schwierigkeit dabei ist der Aufbau und die Pflege eines Index, der nahezu alle Webseiten enthalten sollte. Dazu setzen Suchmaschinenbetreiber sog. Webcrawler ein, die automatisiert das Web durchsuchen, indem sie den Links der Webseiten folgen und die Webseiten zusammen mit ihren Stichworten speichern.
Die weltweit mit Abstand am meisten genutzte Suchmaschine ist Google, mit einem Anteil von ca. 70 % an allen Suchanfragen. Danach folgt die in China populäre Suchmaschine Baidu mit ca. 10 % und die Suchmaschine Bing von Microsoft mit ebenfalls ca. 10 %. Fast alle anderen Suchmaschinen verwenden ohnehin entweder den Google- oder den Bing-Index, wie z. B. Yahoo (Bing-Index) oder web.de (Google-Index).


Eine Alternative zu den gängigen Suchmaschinen, die das Suchverhalten und die gesuchten Seiten erfassen (tracken), ist die Browser-Suchmaschinen-Kombination „Cliqz“. Cliqz wahrt die Anonymität, da es keinerlei persönliche Daten sammelt oder Eingaben speichert. Außerdem bietet Cliqz eine Tracking-Blockade, die verhindert, dass Webseiten den Standort oder andere persönliche Daten ermitteln.

Versionen des WWW
Web 1.0 (statisches Web)
In der ersten Version des WWW gab es nur statische, d. h. unveränderliche, Webseiten. Hier konnten Besucher die Webseite nur betrachten und lesen und über die Links zu anderen Webseiten folgen. Webseiten konnten in dieser Version nicht interaktiv und individuell auf Benutzer reagieren. Benutzereingaben prinzipiell waren im Großen und Ganzen nicht möglich. Webseiten wurden im Web 1.0 nur von Wenigen gestaltet und verändert und von Vielen passiv konsumiert.
Web 2.0 (dynamisches Web)
Mit der Weiterentwicklung des WWW kamen nun dynamische Webseiten hinzu, auf denen Anwender selber den Inhalt gestalten können. Im Web 2.0 können Anwender über verschiedenste Kommunikationsplattformen Meinungen und Medien austauschen, und dabei Inhalt in Form von Text, Bilder etc. hochladen und so die Webseite selber verändern. Der Begriff Social Media entstand in dieser Phase, da nun über das Internet soziale Kontakte aufgebaut und gepflegt werden konnten.
Im Web 2.0 können Webseiten interaktiv auf Anwender reagieren, wie eine lokal installierte Applikation. Hierzu zählen z. B. Email-Dienste wie Gmail, Online-Messenger wie die Web-Variante von Skype oder Online-Spiele. Diese als Online-Dienste über das Internet angebotenen Anwendungen werden Webanwendungen oder Webapplikationen genannt. Dafür waren vor allem auch serverseitig ganz neue Technologien erforderlich, um z. B. den Inhalt einer Webseite dynamisch aus einer Datenbank zu laden.
Eine genaue zeitliche Eingrenzung, ab wann das WWW als Web 2.0 angesehen werden kann gibt es nicht, aber der Prozess der immer dynamischer werdenden Webseiten begann bereits vor der Jahrtausendwende und wird von einigen Experten 2004/2005 als etabliert angesehen. 2004 wurde die erste Web-2.0-Konferenz abgehalten, die jährlich bis ins Jahr 2011 wiederholt wurde. 2005 veröffentlichte Tim O‘Reilly einen Artikel, der das Web 2.0 grundlegend erklärte und deren Prinzipien in der legendären „Tagcloud“ von Markus Angermeier am 11. November 2005 veröffentlicht wurde.

Tagcloud von Markus Angermeier
Web 3.0 (semantisches Web)
Die Schwäche des derzeit existierenden Web 2.0 liegt darin, dass die Informationen, so wie sie derzeit im Web präsentiert werden, von Menschen, aber nicht von Maschinen (Computerprogrammen) verstanden und verarbeitet werden können. Was genau ein Wort bedeutet, können Menschen aus dem Kontext schließen. Für Computerprogramme ist dies wesentlisch schwieriger. Die Idee hinter dem semantischen Web ist, den Inhalt mit seiner Bedeutung zu hinterlegen. Das semantische Web wird zwar von vielen als sehr sinnvoll erachtet, die derzeitigen Umsetzungsversuche sind jedoch sehr komplex und eher theoretischer Natur. Ob sich das semantische Web als nächste Evolutionsstufe des WWW in Form des Web 3.0 durchsetzen wird ist derzeit noch offen.